What is spaCy?
spaCy is an open-source natural language processing (NLP) library initially produced by the company explosion.ai. It has a large community following that has expanded its initial NLP capabilities across multiple languages (now 72+), expanded its capabilities for additional use-cases (such as clinical NLP with medspaCy), and integrates with other ML/DL frameworks (such as torchtext with PyTorch).
One of the great things about spaCy is that is was designed for building production-grade applications. Once you ship train your model with spaCy, you can build applications that can process corpuses of text or preprocess text for deep learning applications.
Creating a playground environment
To get started with spaCy, we will create a virtual environment that will contain spaCy-related packages. Most of the content can be found in the spaCy installation instructions, but additional context is provided below if you are unfamiliar with creating virtual environments.
If you don’t have a directory specifically dedicated for Python environments, let’s create a hidden directory called .env using bash.
Loading the spaCy NLP pipeline
Once you have installed spacy, you can load an object (usually denoted as nlp in tutorials) that includes the processing pipeline and language-specific rules for other NLP-related tasks like tokenization.
Note that you also have to load a trained pipeline with a corresponding language model to perform your language tasks. We’ll download a small English pipeline using the terminal command python -m spacy download <lang-model> to get started:
If you’re interested in other languages and trained pipelines, you can check out the quick start guide here.
Finally, to load the pipeline, you can call the spacy.load(<lang>) method. Note that the pipeline is typically assigned to the variable nlp in most cases and examples online, but you can name the object whatever you want. To see what functions are readily available in the nlp pipeline, you can use the .pipe_names method.
By default, there are several methods returned from the nlp pipeline object, shown below.
Depending on your use-case and the number of documents you are processing with spaCy, you may want to disable some of these components to make spaCy more performant and get around memory issues. More on that later.
Speaking of Performance: Running spaCy with a GPU
Note that if you are interested in running spaCy with a GPU, you need to also install the dependency cupy (documentation for installation can be found here). You will need to specify your CUDA version.
The code below installs cuda and will let spaCy autodetect the cuda version to use, which allows you to install spaCy for a CUDA-compatible GPU.
Once you have the packages installed, you need to call spacy.prefer_gpu or spacy.require_gpu before your pipeline is loaded.
Using spaCy for a single document
In this section we’ll go over some of the out-of-the-box text processing steps performed in the nlp pipeline.
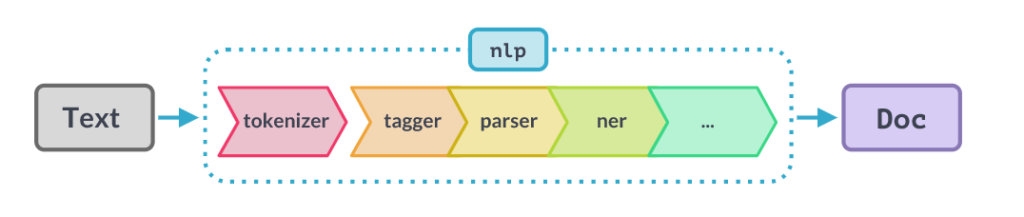
A spaCy pipeline is held by the Language class, and it consists of three components:
- The weights
- A pipeline of functions
- Language data
We can load a spaCy pipeline using the following code block.
When we print the result, note that when we print the document object, it looks like we print out the string representation. However, when we print the document object type, it is actually a spacy.tokens.doc.Doc object!
There are several other methods you can call to doc that we’ll discuss below to get the output from the NLP pipeline. While it seems like such a simple function call, the nlp pipeline integrates multiple text processing components simultaneously. This is what makes spaCy so appealing for most NLP use-cases.
Tokenization
Tokenization is a key process in any NLP pipeline, where the text data is converted into discrete elements called tokens (e.g. sentences, words, subwords, etc). These tokens are the base units that are used by whatever NLP algorithm you intend to use.
Here’s the magic: after feeding your text into the nlp pipeline, you can call on different elements within the object, as the text has already been tokenized for you! For example, the code below will turn the string above into a Doc object. From this Doc object, we’ll grab the tokens within the sentence.
In the list comprehension above, note that each token iterated is a separate object. To get the string representation, you need to call token.text during the iteration.
Tagging
Part-Of-Speech tagging (POS tagging) automatically assigns grammatical tags to each token and it describes the structure of lexical terms within the corpus. This includes whether a token is a noun, adj, adverb, etc, but the type of tagging can become much more granular depending on the use-case.
POS tags are used in several NLP tasks such as lemmatization and Named Entity Recognition, and can distinguish word sense and can be used to infer sematic information within a sentence.
In spaCy, POS tagging is handled by the tagger module. If you want to get the POS of any given token, you can get it using the .pos_ object.
Dependency Parsing
Now assigning tags to tokens is an important NLP task, but alone it doesn’t really tell us anything about the context and relationship between tokens in a phrase or sentence.
Dependency parsing is the task of determining the relationship or dependencies between between lexical units (e.g. words or phrases), using the grammatical structure of a sentence.
Noun chunks
One way we leverage dependency parsing in several common NLP tasks is extracting noun chunks. Noun chunks are phrases that represent nouns and the words that depend on, and accompany nouns. Determining these relationships serves as the basis for several other NLP tasks such as named entity recognition.
To get noun chunks in a document, we can iterate over the Doc.noun_chunks objects:
Parse trees
Long sentences or phrases can be incredibly complex, and establish complicated relationships between chunks. If we want a visual way to understand the hierarchy of dependencies between different these tokens, we can use a parse tree.
Let’s take the example below, which was visualized using displacy, a built in module in the spaCy library.
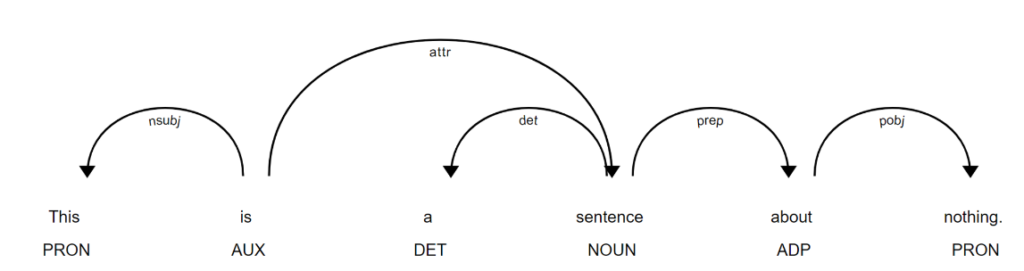
Let’s break down this parse tree:
- Each token in the sentence is a node in the graph.
- There is a root node, which represents the main verb of the sentence.
- Additionally, each edge reflects a directional relationship between nodes, where the flow in the hierarchy goes from parent to child nodes.
- Finally, each node has a label that reflects the POS of the token, while the edges represent syntactic dependency labels, which help us understand the relationship between tokens.
Named Entity Recognition (NER)
Information extraction is the tedious process of going through unstructured data (e.g. text) and extracting the vital information you’re seeking.
When we’re trying to extract information from text, we’re often interested in identifying named-entities (think specific people, organizations, locations, etc). The process of extracting named-entities is called Named Entity Recognition (NER), which builds upon the POS tagging and dependency parsing tasks we’ve describe so far.
In NER, we can essentially frame it as a classification problem, where the goal is to identify entities and classify them into different categories.
Let’s take a look at a new example, where we’ll visualize a new sentence using spaCy and visualize it with displaCy.

As you can see from the example above, the NER model was able to classify a person, organization, and date from a sentence automatically!
Lemmatization and Stemming
When modeling natural languages, one common issue we have to contend with are the small variations in words that have the same meaning. An example of these variations includes contractions (e.g. you’re and you are) – both may be expressed in the same document. If these are not treated, these are seen by the model as different objects, which can reduce model performance and model explainability.
Text normalization is the process of standardizing text, which solves this issue. Stemming and lemmatization are two common text normalization techniques. We’ll go over how to use spaCy for lemmatization and stemming.
Stemming
Stemming is the process of reducing words to their root form (for example, “running” and “runner” should reduce to “run”). Why would you want to stem a word? You can group similar words by reduce related words to the same stem. This also reduces the number of unique tokens that need to be processed by an an algorithm which can increase processing speed.
However, stemming does not work for all natural language tasks, and you have to be cautious when stemming. Stemming can sometimes reduce words to meaningless stems (such as “beauti” for “beautiful”), which can negatively impact the performance of the model. Additionally, stemming can sometimes result in errors where different words are reduced to the same stem even though they have different meanings (such as “bank” and “banker” both being reduced to “bank”).
Due to these potential issues, spaCy doesn’t provide functions for stemming. Instead, spaCy chooses to go through the lemmatization route.
Lemmatization
Lemmatization is similar to stemming, in that it reduces words to a common root. However, in contrast to stemming, lemmatization uses the POS and context of a word to do this reduction. For example, you should see that “running”, “runner”, and “ran” reduces to the lemma “run”.
While lemmatization can provide more accurate shortenings than stemming, it does require more processing power. However, spaCy does this pretty efficiently with the help of a language-specific dictionary, and can return the exact root word!
To get the lemmas in a spaCy pipeline, you can call token.lemma_:
Text Categorization
Text categorization is a classification task that categorizes multiple pieces of text (documents, paragraphs, sentences) into different groups.
There are many classic examples of relevant text categorization problems that have been implemented into products. For example, spam filters automatically separate out real emails from spam based on certain keywords in the text.
There are several steps we need to do to run a text categorization algorithm using spaCy:
- Data preparation
- Model training
- Model evaluation
- Model inference
- Deployment and packaging
We’ll cover these steps in-depth in an upcoming blog post.
Summary
This article provides an introduction to spaCy, an open-source natural language processing (NLP) library that enables you to process text and train NLP models with production-grade scalability in-mind.
I cover how to get started with spaCy for a single document, loading the NLP pipeline, and using spaCy for tasks such as tokenization, part-of-speech tagging, dependency parsing, named entity recognition, lemmatization, and text categorization.
I hope that this post helps out with your NLP projects! If you have additional questions, comments, or would like to say hi, connect with me on LinkedIn or email me. The code written in this tutorial can be found in this GitHub repo: https://github.com/ScottCampit/intro-to-spacy.
Leave a Reply